# A tibble: 7,107 × 19
forested year elevation eastness northness roughness tree_no_tree dew_temp
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <dbl>
1 Yes 2005 881 90 43 63 Tree 0.04
2 Yes 2005 113 -25 96 30 Tree 6.4
3 No 2005 164 -84 53 13 Tree 6.06
4 Yes 2005 299 93 34 6 No tree 4.43
5 Yes 2005 806 47 -88 35 Tree 1.06
6 Yes 2005 736 -27 -96 53 Tree 1.35
7 Yes 2005 636 -48 87 3 No tree 1.42
8 Yes 2005 224 -65 -75 9 Tree 6.39
9 Yes 2005 52 -62 78 42 Tree 6.5
10 Yes 2005 2240 -67 -74 99 No tree -5.63
# ℹ 7,097 more rows
# ℹ 11 more variables: precip_annual <dbl>, temp_annual_mean <dbl>,
# temp_annual_min <dbl>, temp_annual_max <dbl>, temp_january_min <dbl>,
# vapor_min <dbl>, vapor_max <dbl>, canopy_cover <dbl>, lon <dbl>, lat <dbl>,
# land_type <fct>Data budget/making a model
Lecture 3
September 3, 2024
Data on forests in Washington
- The U.S. Forest Service maintains ML models to predict whether a plot of land is “forested.”
- This classification is important for all sorts of research, legislation, and land management purposes.
- Plots are typically remeasured every 10 years and this dataset contains the most recent measurement per plot.
- Type
?forestedto learn more about this dataset, including references.

Data on forests in Washington
N = 7,107plots of land, one from each of 7,107 6000-acre hexagons in WA.- A nominal outcome,
forested, with levels"Yes"and"No", measured “on-the-ground.” - 18 remotely-sensed and easily-accessible predictors:
- numeric variables based on weather and topography.
- nominal variables based on classifications from other governmental orgs.

Data splitting and spending






The whole game - status update
To specify a model
- Choose a model
- Specify an engine
- Set the mode
To specify a model
- Choose a model
- Specify an engine
- Set the mode
To specify a model
- Choose a model
- Specify an engine
- Set the mode
To specify a model
- Choose a model
- Specify an engine
- Set the mode
Logistic regression

Logistic regression

Logistic regression

- Logit of outcome probability modeled as linear combination of predictors:
\(\log(\frac{p}{1 - p}) = \beta_0 + \beta_1 \times \text{A}\)
- Find a sigmoid line that separates the two classes
Decision trees

Decision trees

Series of splits or if/then statements based on predictors
First the tree grows until some condition is met (maximum depth, no more data)
Then the tree is pruned to reduce its complexity
Decision trees


All models are wrong, but some are useful!
Logistic regression

Decision trees

Workflows bind preprocessors and models
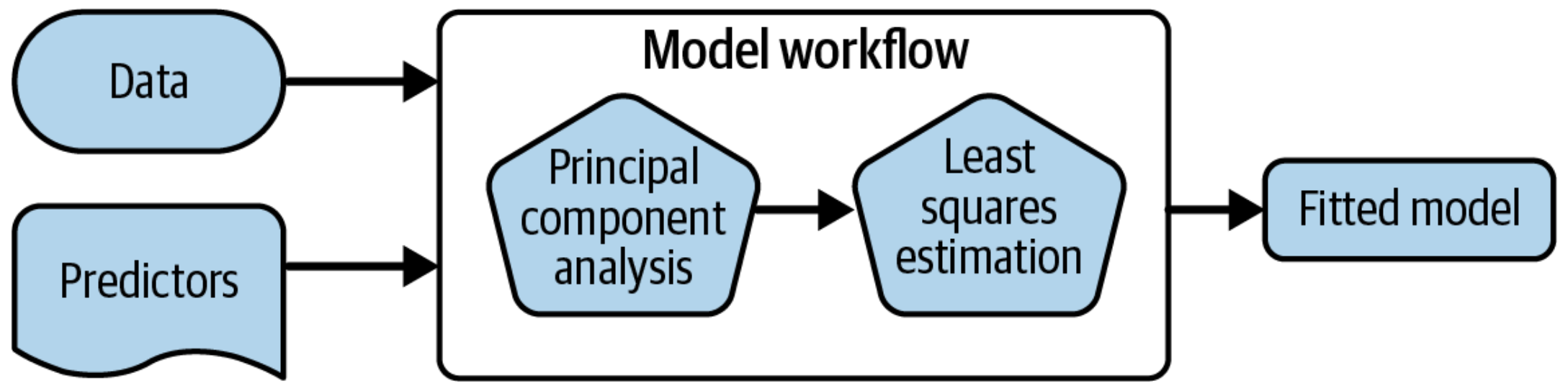
What is wrong with this?
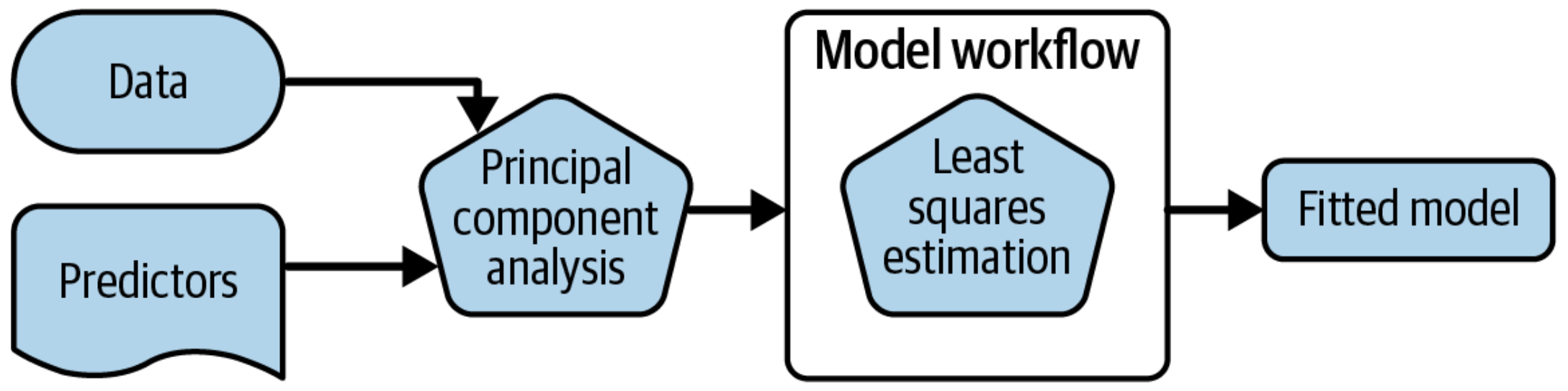
Understand your model
How do you understand your new tree_fit model?

The whole game - status update
My latest school tax bill

