Exploratory data analysis
Lecture 9
September 26, 2024


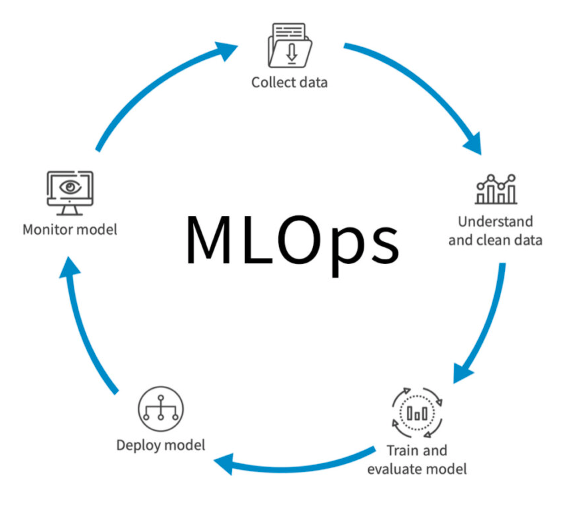
Features of exploratory data analysis

Features of confirmatory data analysis
ggplot(
data = penguins,
mapping = aes(
x = body_mass_g,
y = flipper_length_mm
)
) +
geom_point(alpha = .1) +
geom_smooth(se = FALSE) +
scale_x_continuous(labels = label_number(scale_cut = cut_si("g"))) +
scale_y_continuous(labels = label_number(scale_cut = cut_si("mm"))) +
labs(
title = "Relationship between body mass and\nflipper length of a penguin",
subtitle = str_glue("Sample of {nrow(penguins)} penguins"),
x = "Body mass",
y = "Flipper length"
) +
theme_minimal(
base_family = "Atkinson Hyperlegible",
base_size = 14
) +
theme(plot.title.position = "plot")
Coffee consumption in the United States

Visualizing missingness patterns

Visualizing missingness patterns

Visualizing missingness patterns

Apple Harvest Festival

