Publishing models as APIs
Lecture 15
Cornell University
INFO 4940/5940 - Fall 2025
October 21, 2025
Announcements
Announcements
- Updates to Posit Workbench
- Project 01 EDA due Thursday
Learning objectives
- Create bundled model objects that can be saved to disk
- Implement versioning for model objects
- Review application programming interfaces (APIs)
- Generate a REST API for a model using Vetiver
Application exercise
ae-14
Instructions
- Go to the course GitHub org and find your
ae-14(repo name will be suffixed with your GitHub name). - Clone the repo in Positron, run
renv::restore()to install the required packages, open the Quarto document in the repo, and follow along and complete the exercises. - Render, commit, and push your edits by the AE deadline – end of the day
MLOps
MLOps with {vetiver}
Vetiver, the oil of tranquility, is used as a stabilizing ingredient in perfumery to preserve more volatile fragrances.
If you develop a model…
you can operationalize that model!
If you develop a model…
you likely should be the one to operationalize that model!
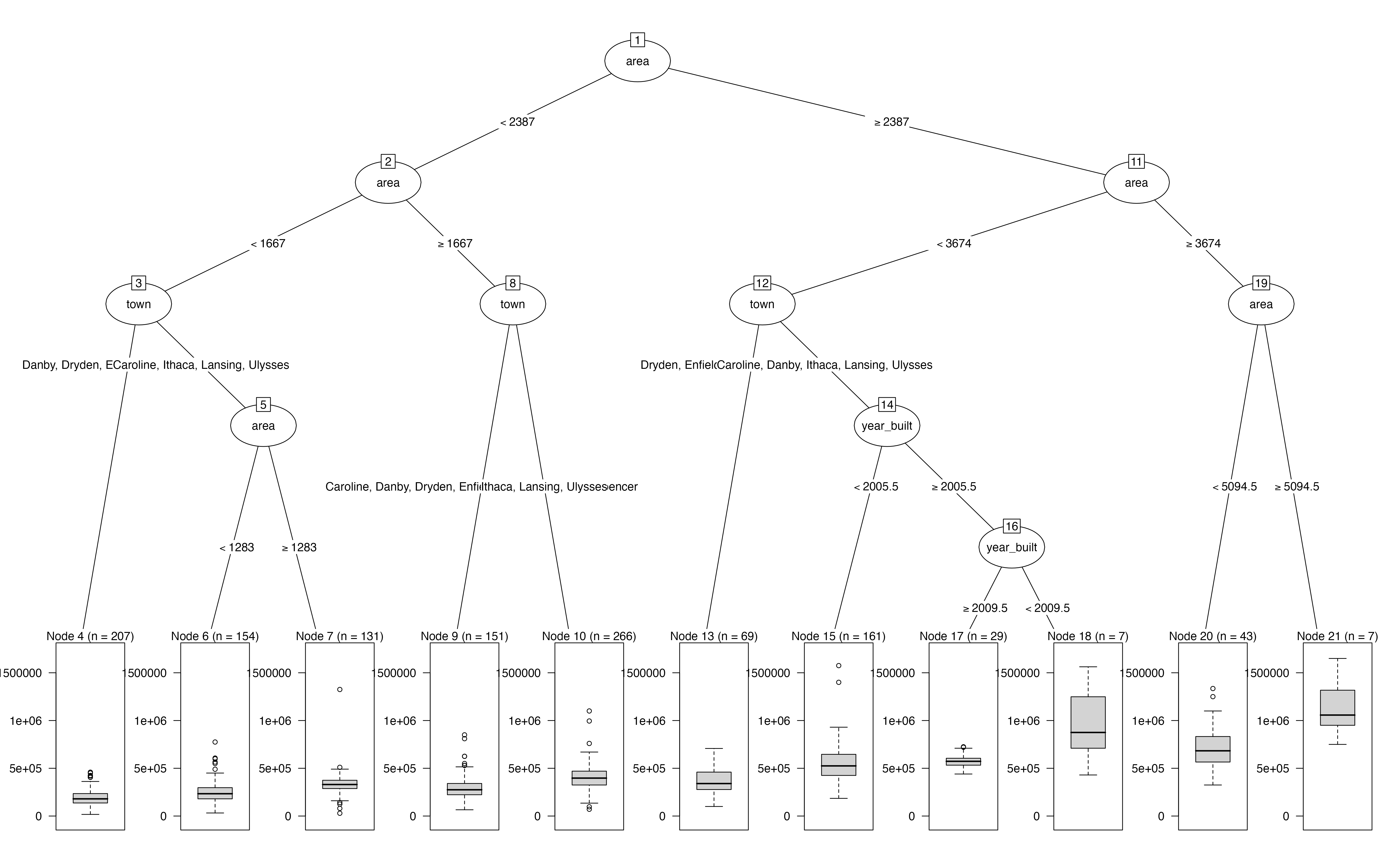
Tompkins County housing data
Tompkins County housing data
- Home sale prices for Tompkins County, NY between 2022-23
- Can certain measurements be used to predict the sale price?
- Data collected from Redfin
Tompkins County housing data
R
Python
- N = 1,225
- A numeric outcome,
price - Other variables to use for prediction:
beds,baths,area, andyear_builtare numeric predictorstownandmunicipalitycould be nominal predictorssold_datecould be a date predictor
Home prices in Tompkins County, NY
| sold_date | price | beds | baths | area | lot_size | year_built | hoa_month | town | municipality | long | lat |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2022-08-16 | 335500 | 3 | 2.0 | 1957 | 4.50000000 | 1880 | NA | Ulysses | Unincorporated | -76.67680 | 42.53255 |
| 2022-11-14 | 331500 | 3 | 2.0 | 1416 | 0.58999082 | 1930 | NA | Lansing | Unincorporated | -76.50347 | 42.53340 |
| 2022-03-31 | 302385 | 3 | 1.5 | 1476 | 0.20000000 | 1900 | NA | Ithaca | Ithaca city | -76.50439 | 42.44250 |
| 2022-09-28 | 285000 | 3 | 2.0 | 1728 | 0.46999541 | 2002 | NA | Dryden | Dryden village | -76.29495 | 42.48415 |
| 2022-07-22 | 350000 | 4 | 1.0 | 1698 | 0.12396694 | 1925 | NA | Ithaca | Ithaca city | -76.50146 | 42.43264 |
| 2023-11-28 | 225000 | 2 | 1.5 | 1047 | 0.08000459 | 1939 | NA | Ithaca | Ithaca city | -76.50576 | 42.43373 |
| 2023-09-13 | 285000 | 3 | 2.0 | 2311 | 1.26999541 | 1965 | NA | Caroline | Unincorporated | -76.33375 | 42.39048 |
| 2023-06-23 | 145000 | 2 | 2.0 | 1215 | 0.03999082 | 1990 | NA | Danby | Unincorporated | -76.49228 | 42.38340 |
| 2023-11-27 | 90900 | 5 | 3.0 | 2238 | 0.38000459 | 1880 | NA | Groton | Groton village | -76.36311 | 42.58533 |
| 2022-11-09 | 467500 | 6 | 4.0 | 2304 | 0.13000459 | 2017 | NA | Ithaca | Ithaca city | -76.50205 | 42.43136 |
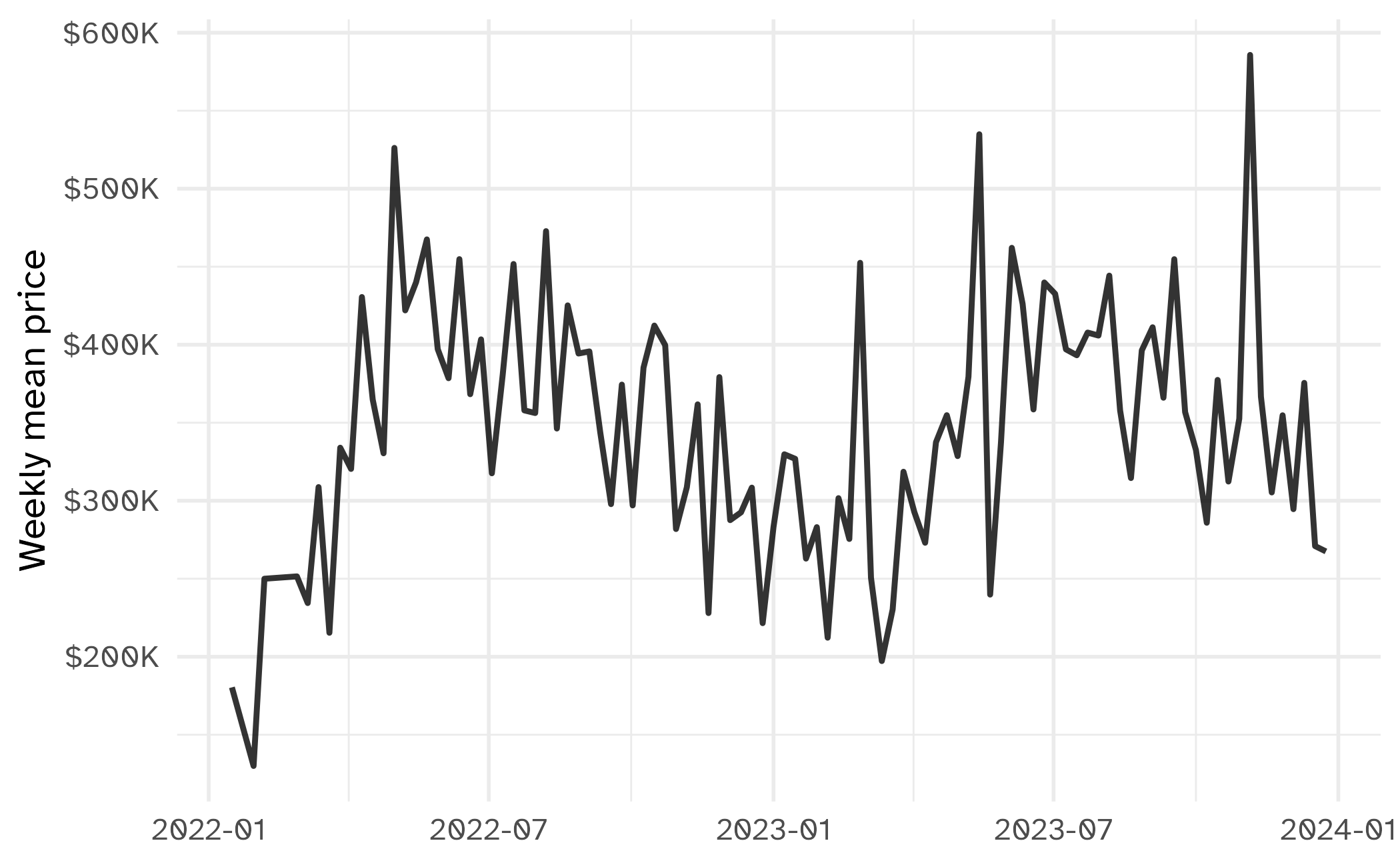
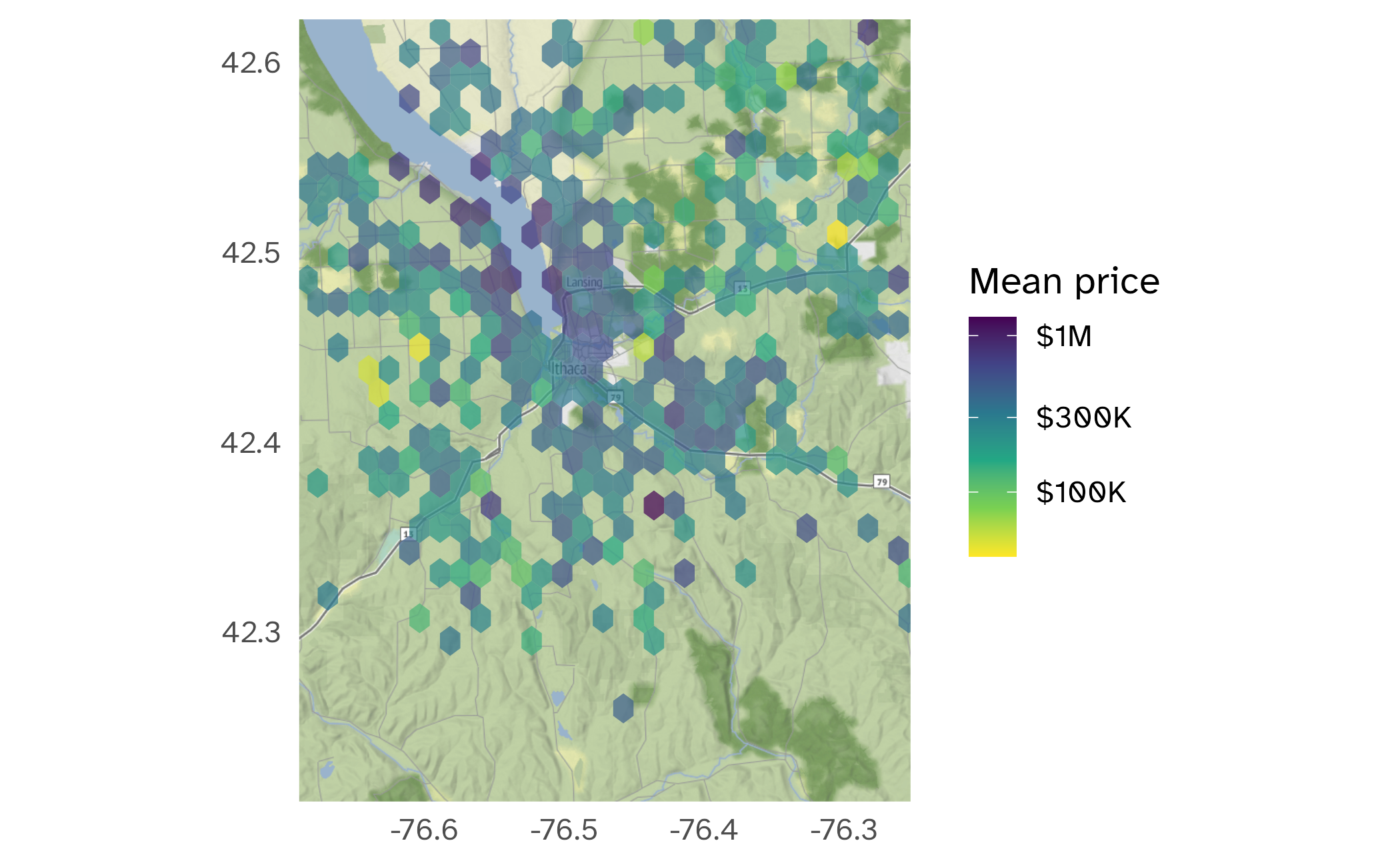
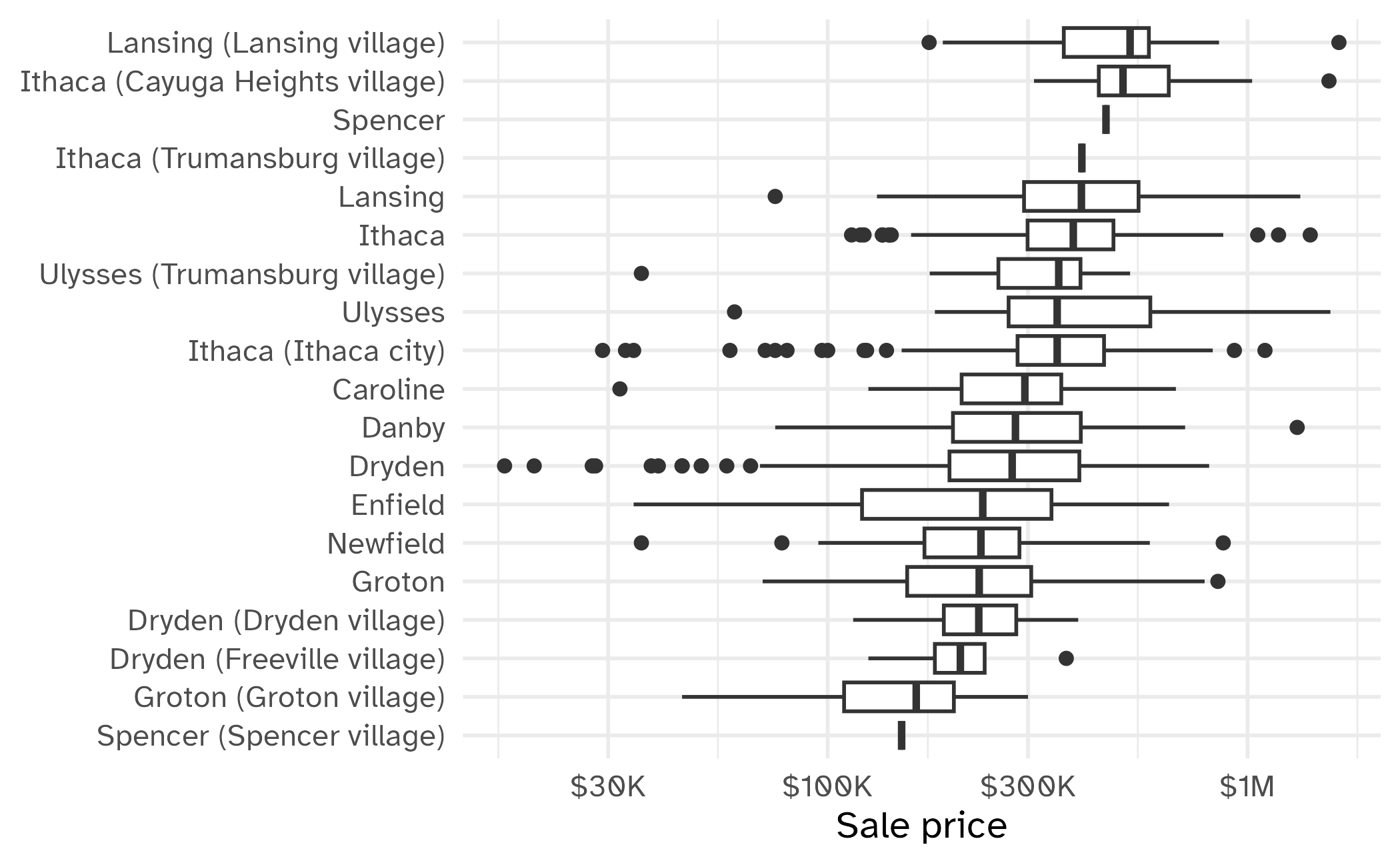
Time for building a model!
Spend your data budget
R
Python
Fit a linear regression model 🚀
Or your model of choice!
R
Python
📝 Fit a model
Instructions
Split your data in training and testing.
Fit a model to your training data.
03:00
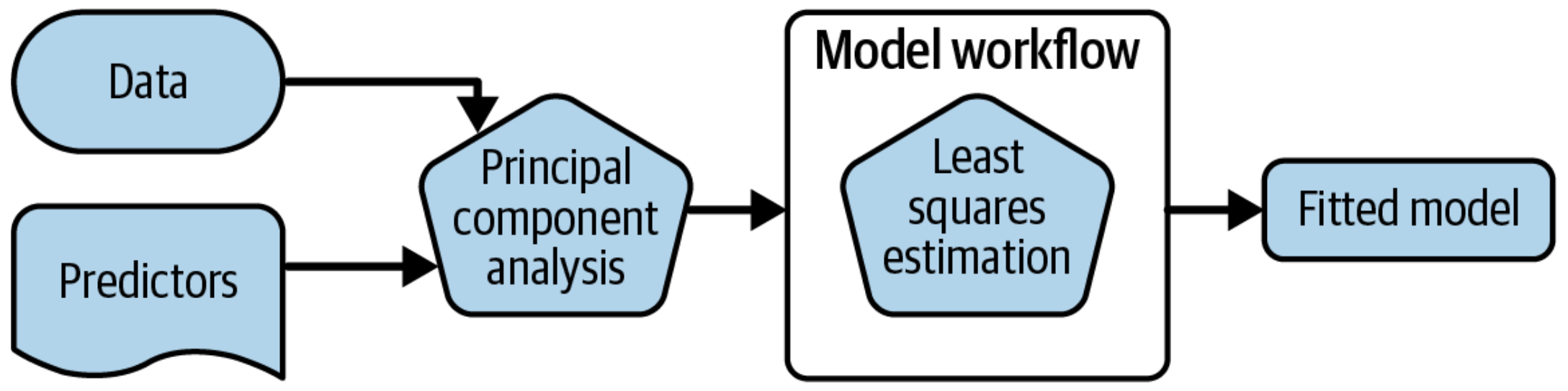
Create a deployable bundle
Deploy preprocessors and models together
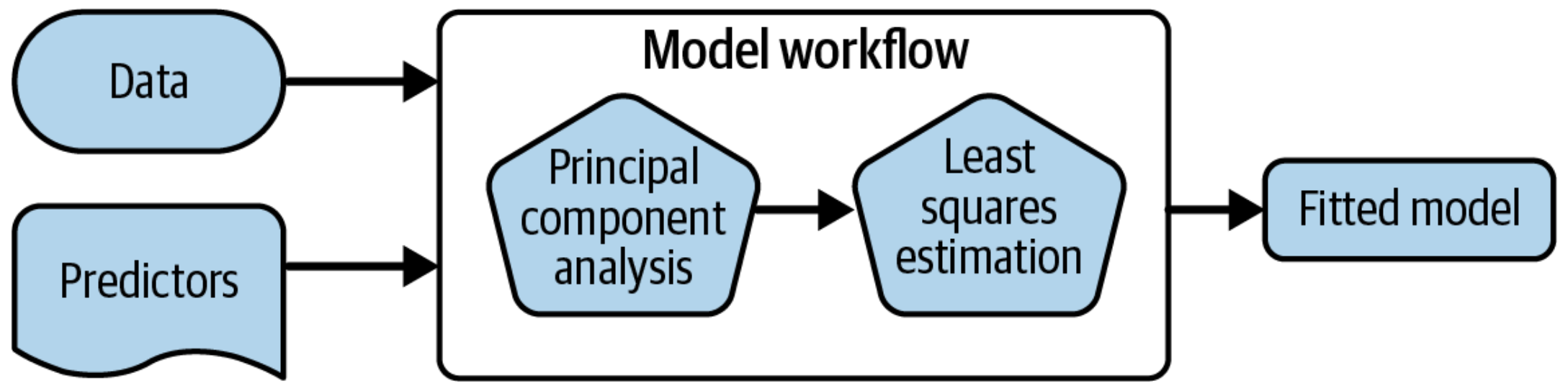
Create a deployable model object
R
── tompkins-housing ─ <bundled_workflow> model for deployment
A lm regression modeling workflow using 4 featuresPython
Deploy preprocessors and models together
What is wrong with this?
📝 Create a vetiver model object
Instructions
Create your vetiver model object.
Check out the default description that is created, and try out using a custom description.
Show your custom description to your neighbor.
05:00
Version your model
How could you share your resources?
Data, models, R/Python objects, etc.
❌ Email
❌ GitHub
🫤 Shared network drive
🫤 Dropbox, Google Drive, Box.com, etc.
✅ Amazon S3
✅ Azure
✅ Google Cloud
✅ Microsoft 365
pins 📌
The pins package publishes data, models, and other R and Python objects, making it easy to share them across projects and with your colleagues.
Pin your model
Creating new version '20251022T155624Z-64a74'
Writing to pin 'tompkins-housing'
Create a Model Card for your published model
• Model Cards provide a framework for transparent, responsible reporting
• Use the vetiver `.Rmd` template as a place to startModel Cards provide a framework for transparent, responsible reporting.
Use the vetiver `.qmd` Quarto template as a place to start,
with vetiver.model_card()
Writing pin:
Name: 'tompkins-housing'
Version: 20251022T115624Z-1ee78📝 Pin your model
Instructions
Pin your vetiver model object to a temporary board.
Retrieve the model metadata with pin_meta().
05:00
Version your model
Fit a random forest
rf_rec <- recipe(
price ~ beds + baths + area + year_built + town,
data = housing_train
) |>
step_impute_mean(all_numeric_predictors()) |>
step_impute_mode(all_nominal_predictors())
housing_fit <- workflow() |>
add_recipe(rf_rec) |>
add_model(rand_forest(trees = 200, mode = "regression")) |>
fit(data = housing_train)from sklearn.ensemble import RandomForestRegressor
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Define feature columns
numeric_features = ["beds", "baths", "area", "year_built"]
categorical_features = ["town"]
# Create preprocessing steps
numeric_transformer = SimpleImputer(strategy="mean")
categorical_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
])
# Combine preprocessors
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features)
]
)
# Create pipeline with preprocessor and model
housing_fit = Pipeline(steps=[
("preprocessor", preprocessor),
("regressor", RandomForestRegressor(n_estimators=200, random_state=123))
])
# Prepare training data with all features
X_train_full = housing.loc[X_train.index, numeric_features + categorical_features]
housing_fit.fit(X_train_full, y_train)Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('num', SimpleImputer(),
['beds', 'baths', 'area',
'year_built']),
('cat',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder(handle_unknown='ignore'))]),
['town'])])),
('regressor',
RandomForestRegressor(n_estimators=200, random_state=123))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| steps | [('preprocessor', ...), ('regressor', ...)] | |
| transform_input | None | |
| memory | None | |
| verbose | False |
Parameters
| transformers | [('num', ...), ('cat', ...)] | |
| remainder | 'drop' | |
| sparse_threshold | 0.3 | |
| n_jobs | None | |
| transformer_weights | None | |
| verbose | False | |
| verbose_feature_names_out | True | |
| force_int_remainder_cols | 'deprecated' |
['beds', 'baths', 'area', 'year_built']
Parameters
| missing_values | nan | |
| strategy | 'mean' | |
| fill_value | None | |
| copy | True | |
| add_indicator | False | |
| keep_empty_features | False |
['town']
Parameters
| missing_values | nan | |
| strategy | 'most_frequent' | |
| fill_value | None | |
| copy | True | |
| add_indicator | False | |
| keep_empty_features | False |
Parameters
| categories | 'auto' | |
| drop | None | |
| sparse_output | True | |
| dtype | <class 'numpy.float64'> | |
| handle_unknown | 'ignore' | |
| min_frequency | None | |
| max_categories | None | |
| feature_name_combiner | 'concat' |
Parameters
| n_estimators | 200 | |
| criterion | 'squared_error' | |
| max_depth | None | |
| min_samples_split | 2 | |
| min_samples_leaf | 1 | |
| min_weight_fraction_leaf | 0.0 | |
| max_features | 1.0 | |
| max_leaf_nodes | None | |
| min_impurity_decrease | 0.0 | |
| bootstrap | True | |
| oob_score | False | |
| n_jobs | None | |
| random_state | 123 | |
| verbose | 0 | |
| warm_start | False | |
| ccp_alpha | 0.0 | |
| max_samples | None | |
| monotonic_cst | None |
Version your model
R
Python
📝 Pin a new version
Instructions
Create a new vetiver model object using your linear regression model that is explicitly versioned = TRUE and pin to your temporary board.
Then train a random forest model and create a new vetiver model object that is also versioned = TRUE with the same name.
Write this new version of your model to the same pin, and see what versions you have with pin_versions().
05:00
Make it easy to do the right thing
Make it easy to do the right thing
- Robust and human-friendly checking of new data
- Track and document software dependencies of models
- Model cards for transparent, responsible reporting
You can deploy your model as a…
REST API
Application programming interface (API)
An interface that can connect applications in a standard way
- Representational State Transfer (REST)
- Uniform Resource Location (URL)
RESTful queries
- Submit request to server via URL
- Return result in a structured format
- Parse results into a local format
Create a vetiver REST API
R
Python
📝 Create a model API
Instructions
Create a vetiver API for your model and run it locally.
Explore the visual documentation.
How many endpoints are there?
Discuss what you notice with your neighbor.
05:00
What does “deploy” mean?

Image credit: Isabel Zimmerman
What does “deploy” mean?

Image credit: Isabel Zimmerman
Where can vetiver deploy?
- Enterprise software platforms such as Posit Connect and AWS SageMaker
- A public or private cloud, using Docker
How do you make a request of your new API?
R
Python
How do you make a request of your new API?
- Python or R packages like
requestsor {httr2} - curl
- There is special support in vetiver for the
/predictendpoint
Any tool that can make an HTTP request can be used to interact with your model API!
Create a vetiver endpoint
You can treat your model API much like it is a local model in memory!
R
Python
📝 Test your predict endpoint
Instructions
Create a vetiver endpoint object for your API.
Predict with your endpoint for new data.
Optional: call another endpoint like /ping or /metadata.
05:00
Wrap-up
Recap
- ML models can be deployed as APIs
- Use pins to share your models
- vetiver can help you bundle, version, and deploy your models
Acknowledgments
- Materials derived in part from Intro to MLOps with {vetiver} and licensed under a Creative Commons Attribution 4.0 International (CC BY) License.