Deploying models to the cloud
Lecture 16
Cornell University
INFO 4940/5940 - Fall 2025
October 23, 2025
Announcements
Announcements
- Project 01 EDA due today
- Homework 05
Learning objectives
- Introduce a container model for deploying models as API
- Define key terms for working with containers and Docker
- Implement Docker containers for model APIs
- Authenticate with cloud storage platforms for model versioning
- Expand Vetiver model APIs through additional metadata and endpoints
Where does Vetiver work?
- Enterprise software platforms such as Posit Connect and AWS SageMaker
- A public or private cloud, using Docker
Docker
Containerized environments for your code
Container
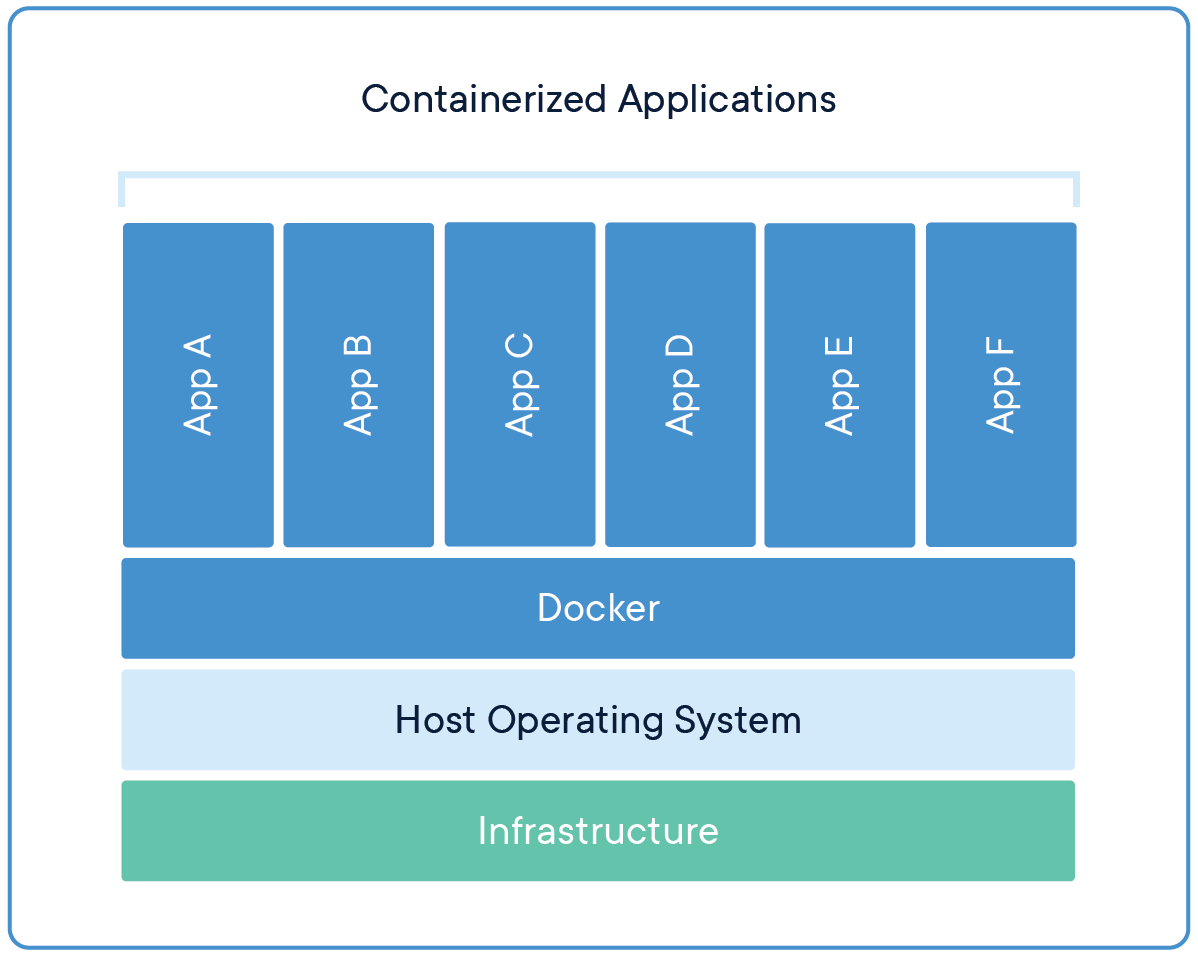
Image credit: What is a container?
Benefits to containers
- Lightweight
- Portable
- Consistent
- Scalable
- Secure
Why Docker?
- Open source
- Reproducible
- Bring your own container philosophy
Create Docker artifacts
Start with a trained and versioned model
Dockerfile- Model dependencies, typically
requirements.txtorrenv.lock - File to serve API, typically
app.pyorplumber.R
Create Docker artifacts
Start with a trained and versioned model
R
Python
Dockerfiles for Vetiver
R
# Generated by the vetiver package; edit with care
FROM rocker/r-ver:4.5.1
ENV RENV_CONFIG_REPOS_OVERRIDE https://packagemanager.rstudio.com/cran/latest
RUN apt-get update -qq && apt-get install -y --no-install-recommends \
libcurl4-openssl-dev \
libicu-dev \
libsodium-dev \
libssl-dev \
libx11-dev \
make \
zlib1g-dev \
&& apt-get clean
COPY vetiver_renv.lock renv.lock
RUN Rscript -e "install.packages('renv')"
RUN Rscript -e "renv::restore()"
COPY plumber.R /opt/ml/plumber.R
EXPOSE 8080
ENTRYPOINT ["R", "-e", "pr <- plumber::plumb('/opt/ml/plumber.R'); pr$run(host = '0.0.0.0', port = 8080)"]Dockerfiles for Vetiver
Python
# # Generated by the vetiver package; edit with care
# start with python base image
FROM python:3.13
# create directory in container for vetiver files
WORKDIR /vetiver
# copy and install requirements
COPY vetiver_requirements.txt /vetiver/requirements.txt
#
RUN pip install --no-cache-dir --upgrade -r /vetiver/requirements.txt
# copy app file
COPY app.py /vetiver/app/app.py
# expose port
EXPOSE 8080
# run vetiver API
CMD ["uvicorn", "app.app:api", "--host", "0.0.0.0", "--port", "8080"]Build your container
Use the Terminal/Shell to build your Docker container
If you have an Apple Silicon Mac
Add the --platform linux/amd64 to install R packages from compiled binaries rather than source.
Run your container
Make predictions
R
Python
Application exercise
ae-15
Instructions
- Go to the course GitHub org and find your
ae-15(repo name will be suffixed with your GitHub name). - Clone the repo in Positron, install required packages using
renv::restore()(R) oruv sync(Python), open the Quarto document in the repo, and follow along and complete the exercises. - Render, commit, and push your edits by the AE deadline – end of the day
📝 Create and build a container
Instructions
Create a Docker container for your model using a board_local().
Build the Docker container and run it locally. Make predictions using the API.
07:00
pins 📌
The pins package publishes data, models, and other R and Python objects, making it easy to share them across projects and with your colleagues.
You can pin objects to a variety of pin boards, including:
- a local folder (like a network drive or even a temporary directory)
- Amazon S3
- Azure Storage
- Databricks
- Google Cloud
- Microsoft 365
Use board_gcs() to connect to Google Cloud Storage
R
Python
Authenticating with cloud storage platforms
- API key
- OAuth token
- Service account
Authenticating with Google Cloud Storage
service-auth.json
Define file location via environment variable
📝 Create and build a container
Instructions
Create a Docker container for your model using board_gcs().
Build the Docker container and run it locally. Make predictions using the API.
R
07:00

Building Vetiver Docker artifacts
vetiver_prepare_docker()/vetiver.prepare_docker() decomposes into two major functions
R
Python
Requires additional tinkering (some automatic, some manual) to ensure correct authentication procedures
📝 Create and build a container
Create the Docker artifacts, build the container, and run it locally. Make predictions using the API.
R
Modify
plumber.Rto load {googleCloudStorageR}Copy
service-auth.jsonto same directory asDockerfileModify
Dockerfileto correctly incorporateservice-auth.json. After therun apt-getstep, add the following lines
Python
Modify
vetiver_requirements.txtto includegcsfsdependencyCopy
service-auth.jsonto same directory asDockerfileModify
Dockerfileto correctly incorporateservice-auth.json. After theCOPY app.pystep, add the following lines
12:00
Docker resources
Model metrics as metadata 🎯
Model metrics as metadata
library(tidyverse)
library(tidymodels)
housing <- read_csv("data/tompkins-home-sales.csv")
set.seed(123)
housing_split <- housing |>
mutate(price = log10(price)) |>
initial_split(prop = 0.8)
housing_train <- training(housing_split)
housing_test <- testing(housing_split)
rf_rec <- recipe(
price ~ beds + baths + area + year_built,
data = housing_train
) |>
step_impute_mean(all_numeric_predictors()) |>
step_impute_mode(all_nominal_predictors())
housing_fit <- workflow() |>
add_recipe(rf_rec) |>
add_model(rand_forest(trees = 200, mode = "regression")) |>
fit(data = housing_train)import pandas as pd
import numpy as np
from sklearn import model_selection, ensemble
housing = pd.read_csv('data/tompkins-home-sales.csv')
np.random.seed(123)
X, y = housing[["beds", "baths", "area", "year_built"]], np.log10(housing["price"])
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y,
test_size = 0.2
)
housing_fit = ensemble.RandomForestRegressor(n_estimators=200).fit(X_train, y_train)Model metrics as metadata
from sklearn import metrics
metric_set = [metrics.root_mean_squared_error, metrics.r2_score, metrics.mean_absolute_error]
y_predictions = pd.Series(housing_fit.predict(X_test))
housing_metrics = pd.DataFrame()
for metric in metric_set:
metric_name = str(metric.__name__)
metric_output = metric(y_test, y_predictions)
housing_metrics = pd.concat(
(
housing_metrics,
pd.DataFrame({"name": [metric_name], "score": [metric_output]}),
),
axis=0,
)
housing_metrics.reset_index(inplace=True, drop=True)
housing_metrics name score
0 root_mean_squared_error 0.195166
1 r2_score 0.493361
2 mean_absolute_error 0.142366Model metrics as metadata
Model metrics as metadata
- We pin our vetiver model to a board to version it
- The metadata, including our metrics, are versioned along with the model
📝 Compute and pin metrics
Instructions
Compute metrics for your model using the testing data.
Store these metrics as metadata in a vetiver model object.
Write this new vetiver model object as a new version of your pin.
05:00
Model metrics as metadata
How do we extract our metrics out to use them?
⏱️ Obtain your metrics
Instructions
Obtain the metrics metadata for your versioned model.
What else might you want to store as model metadata?
How or when might you use model metadata?
07:00
Extensions
- Use
pathargument to create Docker artifacts in a subdirectory (file management) - Add new endpoints to your API to provide additional functionality
- Monitor your deployed model’s statistical performance
Wrap-up
Recap
- Docker containers are a lightweight, portable, and consistent way to deploy code
- Vetiver can help you create Docker artifacts for your models
- Model metrics can be stored as metadata in Vetiver models
Acknowledgments
- Materials derived in part from Intro to MLOps with {vetiver} and licensed under a Creative Commons Attribution 4.0 International (CC BY) License.