Notice: This website contains the materials for INFO 4940/5940 as taught in fall 2024. The course as taught in fall 2025 will be significantly revised.
library(textrecipes)reg_metrics<-metric_set(mae, rsq)data(hotel_rates)set.seed(295)hotel_rates<-hotel_rates|>sample_n(5000)|>arrange(arrival_date)|>select(-arrival_date)|>mutate( company =factor(as.character(company)), country =factor(as.character(country)), agent =factor(as.character(agent)))set.seed(4028)hotel_split<-initial_split(hotel_rates, strata =avg_price_per_room)hotel_train<-training(hotel_split)hotel_test<-testing(hotel_split)
Explore the data
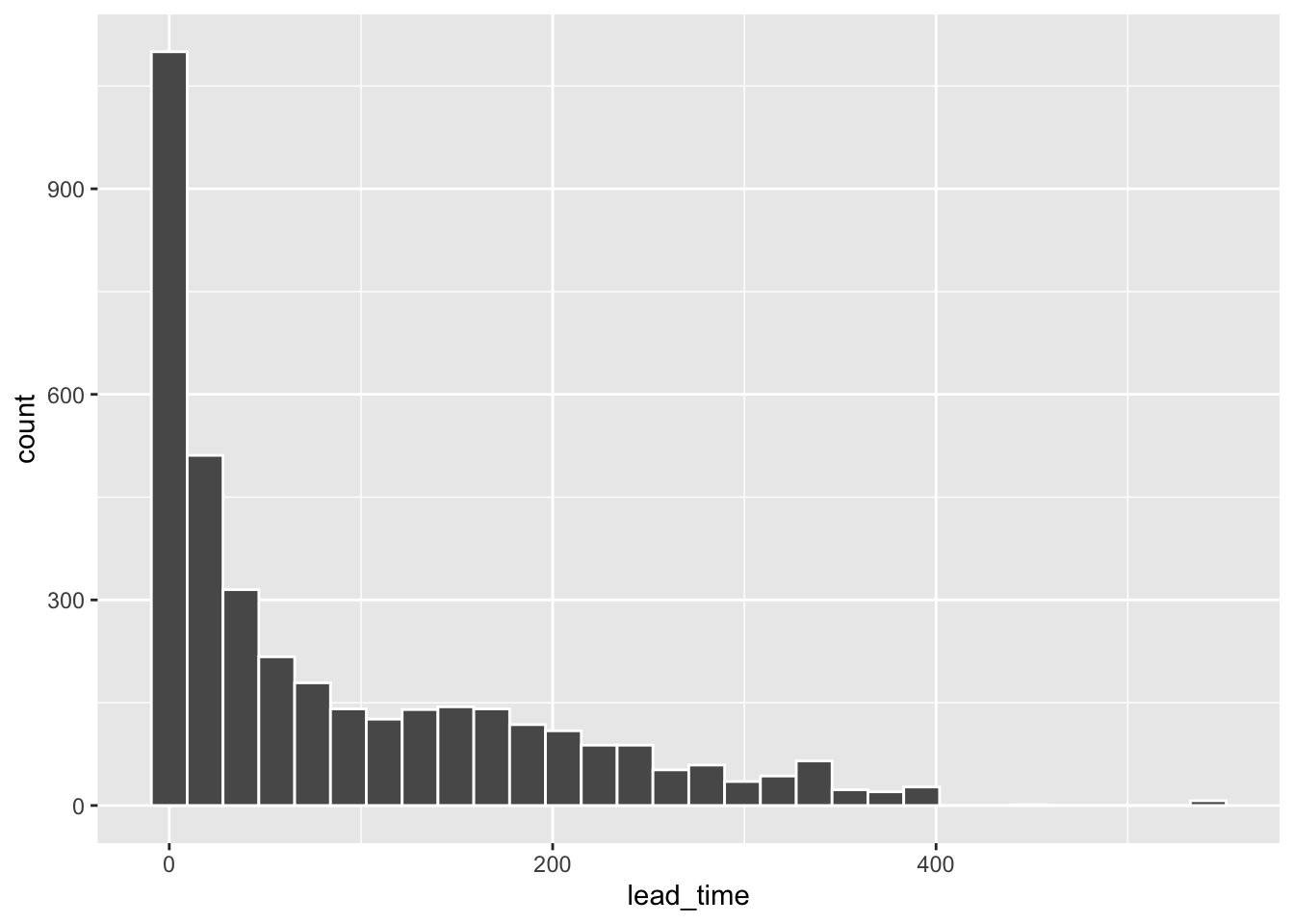
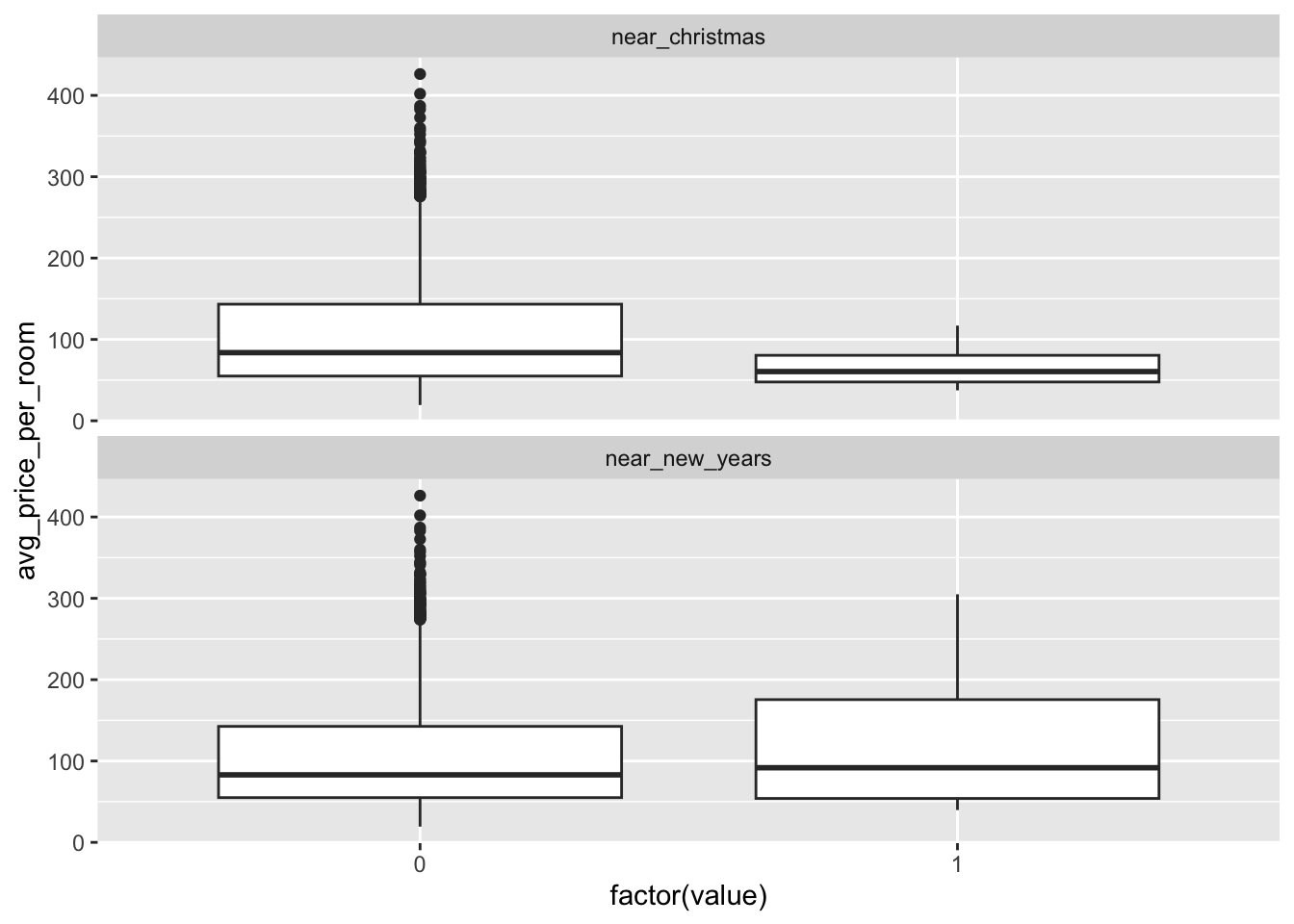
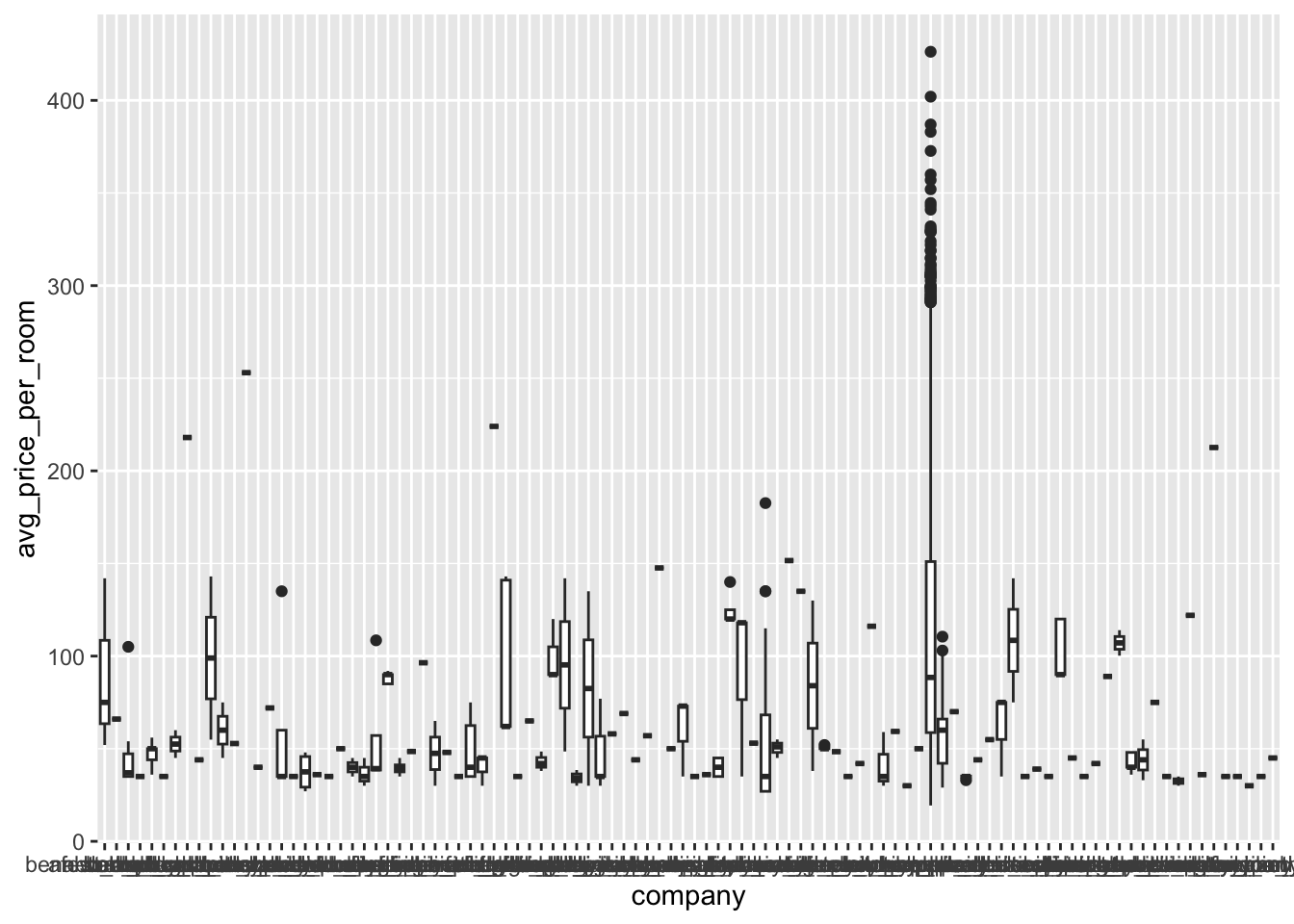
Your turn: Investigate the training data. The outcome is avg_price_per_room. What trends or patterns do you see?
hotel_rec<-recipe(avg_price_per_room~., data =hotel_train)summary(hotel_rec)
# A tibble: 27 × 4
variable type role source
<chr> <list> <chr> <chr>
1 lead_time <chr [2]> predictor original
2 stays_in_weekend_nights <chr [2]> predictor original
3 stays_in_week_nights <chr [2]> predictor original
4 adults <chr [2]> predictor original
5 children <chr [2]> predictor original
6 babies <chr [2]> predictor original
7 meal <chr [3]> predictor original
8 country <chr [3]> predictor original
9 market_segment <chr [3]> predictor original
10 distribution_channel <chr [3]> predictor original
# ℹ 17 more rows
Your turn
What do you think are in the type vectors for the lead_time and country columns?
Add response here. Contains information on both the R data type as well as the substantive type of variable for {recipes} (e.g. numeric, nominal, ordinal).
Create a recipe
Your turn: Create a recipe() for the hotel data to:
use a Yeo-Johnson (YJ) transformation on lead_time
We’ll compute two measures, mean absolute error (MAE) and the coefficient of determination (a.k.a \(R^2\)), and focus on the MAE for parameter optimization.
reg_metrics<-metric_set(mae, rsq)
Your turn: Use fit_resamples() to fit your workflow with a recipe.
Collect the predictions from the results. How did you do?
set.seed(9)# add code herehotel_lm_wflow<-workflow()|>add_recipe(hotel_indicators)|>add_model(linear_reg())ctrl<-control_resamples(save_pred =TRUE)hotel_lm_res<-hotel_lm_wflow|>fit_resamples(hotel_rs, control =ctrl, metrics =reg_metrics)
→ A | warning: prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
There were issues with some computations A: x1
There were issues with some computations A: x6
There were issues with some computations A: x9
collect_metrics(hotel_lm_res)
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 mae standard 16.6 10 0.214 Preprocessor1_Model1
2 rsq standard 0.884 10 0.00339 Preprocessor1_Model1
Fine. MAE is around €16. Not too bad in raw terms. High \(R^2\) value as well.
Holdout predictions
# Since we used `save_pred = TRUE`lm_cv_pred<-collect_predictions(hotel_lm_res)lm_cv_pred|>slice(1:7)
Your turn: What does this plot tell us about the performance of our model?
Add response here. The model is mostly calibrated successfully against the true values, but does have a tendency to under-predict prices for true average rates above 200.