AE 09: Code caching and data preparation
Application exercise
Execute options set in YAML header
Below are the execute options defined in the YAML header.
execute:
cache: true
warning: falsePart 1 - code caching in Quarto
Setup
# metrics
reg_metrics <- metric_set(mae, rsq)
# import data
data(hotel_rates)
set.seed(295)
hotel_rates <- hotel_rates |>
sample_n(5000) |>
arrange(arrival_date) |>
select(-arrival_date) |>
mutate(
company = factor(as.character(company)),
country = factor(as.character(country)),
agent = factor(as.character(agent))
)
# split into training/test sets
set.seed(421)
hotel_split <- initial_split(hotel_rates, strata = avg_price_per_room)
hotel_train <- training(hotel_split)
hotel_test <- testing(hotel_split)
# 10-fold CV
set.seed(531)
hotel_rs <- vfold_cv(hotel_train, v = 5, strata = avg_price_per_room)Create workflow
hash_rec <- recipe(avg_price_per_room ~ ., data = hotel_train) |>
step_YeoJohnson(lead_time) |>
step_dummy_hash(agent, num_terms = tune("agent hash")) |>
step_dummy_hash(company, num_terms = tune("company hash")) |>
step_dummy(all_nominal_predictors()) |>
step_zv(all_predictors())lm_spec <- linear_reg() |>
set_mode("regression") |>
set_engine("lm")
lm_wflow <- workflow(hash_rec, lm_spec)Tune the model
set.seed(9)
lm_res <- lm_wflow |>
tune_grid(
resamples = hotel_rs,
grid = 10,
metrics = reg_metrics
)Inspect results:
autoplot(lm_res)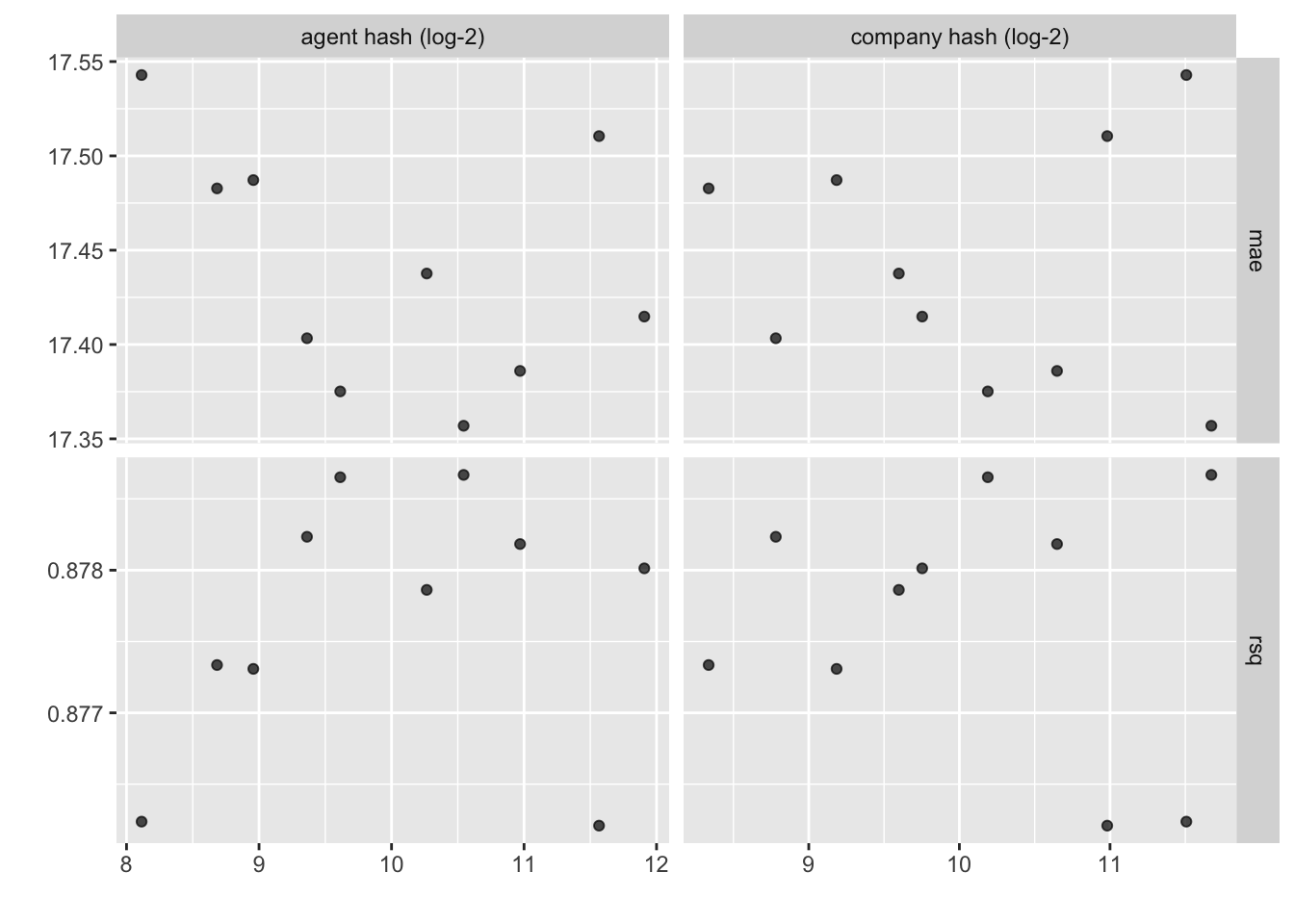
show_best(lm_res, metric = "mae")# A tibble: 5 × 8
`agent hash` `company hash` .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 1493 3265 mae standard 17.4 5 0.212 Preprocess…
2 783 1167 mae standard 17.4 5 0.235 Preprocess…
3 2006 1605 mae standard 17.4 5 0.228 Preprocess…
4 658 440 mae standard 17.4 5 0.200 Preprocess…
5 3842 863 mae standard 17.4 5 0.214 Preprocess…Part 2 - prepare the coffee survey
Your turn: Implement data cleaning/preparation for the coffee survey data set.
Note
Fill in the TODOs with the appropriate code.
library(tidyverse)
library(here)
# load data
coffee_survey <- read_csv(file = here("data/coffee_survey.csv"))
# only keep relevant columns that will be used for modeling
coffee_clean <- coffee_survey |>
select(
TODO
) |>
# convert categorical variables with single answer to factors
mutate(
# convert all initially with factor()
across(
.cols = c(
age, cups, favorite, style, strength, roast_level,
caffeine, prefer_overall, wfh, total_spend, taste:political_affiliation
),
.fns = factor
),
# adjust order of levels for ordinal variables
age = fct_relevel(
.f = age,
"<18 years old",
"18-24 years old",
"25-34 years old",
"35-44 years old",
"45-54 years old",
"55-64 years old",
">65 years old"
),
cups = fct_relevel(
.f = cups,
"Less than 1", "1", "2", "3", "4", "More than 4"
),
strength = fct_relevel(
.f = strength,
TODO
),
caffeine = fct_relevel(
.f = caffeine,
TODO
),
wfh = fct_relevel(
.f = wfh,
"I primarily work from home", "I do a mix of both",
"I primarily work in person"
),
total_spend = fct_relevel(
.f = total_spend,
"<$20"
) |>
fct_relevel(
">$100",
after = 5L
),
across(
.cols = c(most_paid, most_willing),
.fns = \(x) fct_relevel(
.f = x,
TODO
)
),
spent_equipment = fct_relevel(
.f = spent_equipment,
"Less than $20", "$20-$50", "$50-$100", "$100-$300", "$300-$500",
"$500-$1000", "More than $1,000"
),
education_level = fct_relevel(
.f = education_level,
"Less than high school", "High school graduate",
"Some college or associate's degree", "Bachelor's degree",
"Master's degree", "Doctorate or professional degree"
),
number_children = fct_relevel(
.f = number_children,
"None", "1", "2", "3", "More than 3"
),
) |>
# fix additions column to ensure commas are only used to separate values
mutate(
additions = str_replace(
string = additions,
pattern = "TODO",
replacement = "TODO"
),
purchase = str_replace_all(
string = purchase,
pattern = "National chain \\(e.g. Starbucks, Dunkin\\)",
replacement = "National chain \\(e.g. Starbucks Dunkin\\)"
)
) |>
# separate columns with multiple answers into one column per answer
separate_wider_delim(
cols = c(
TODO
),
delim = "TODO",
names_sep = "_",
too_few = "align_start"
) |>
# convert multi-answer columns to factors
mutate(
across(
.cols = c(TODO),
.fns = factor
)
) |>
# drop rows with no prefer_overall
drop_na(TODO) |>
write_rds(file = here("TODO"))Acknowledgments
- Materials for part 1 derived in part from Machine learning with {tidymodels} and licensed under a Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA) License.